

Don't Read the Code
From Inspecting Code to Observing Systems

Disclaimer: this article represents my personal opinions and not my employer’s.
For a long time, reading code was the most practical way to build confidence in a system. It was how engineers debugged, reviewed changes, and resolved ambiguity when documentation and reality diverged.
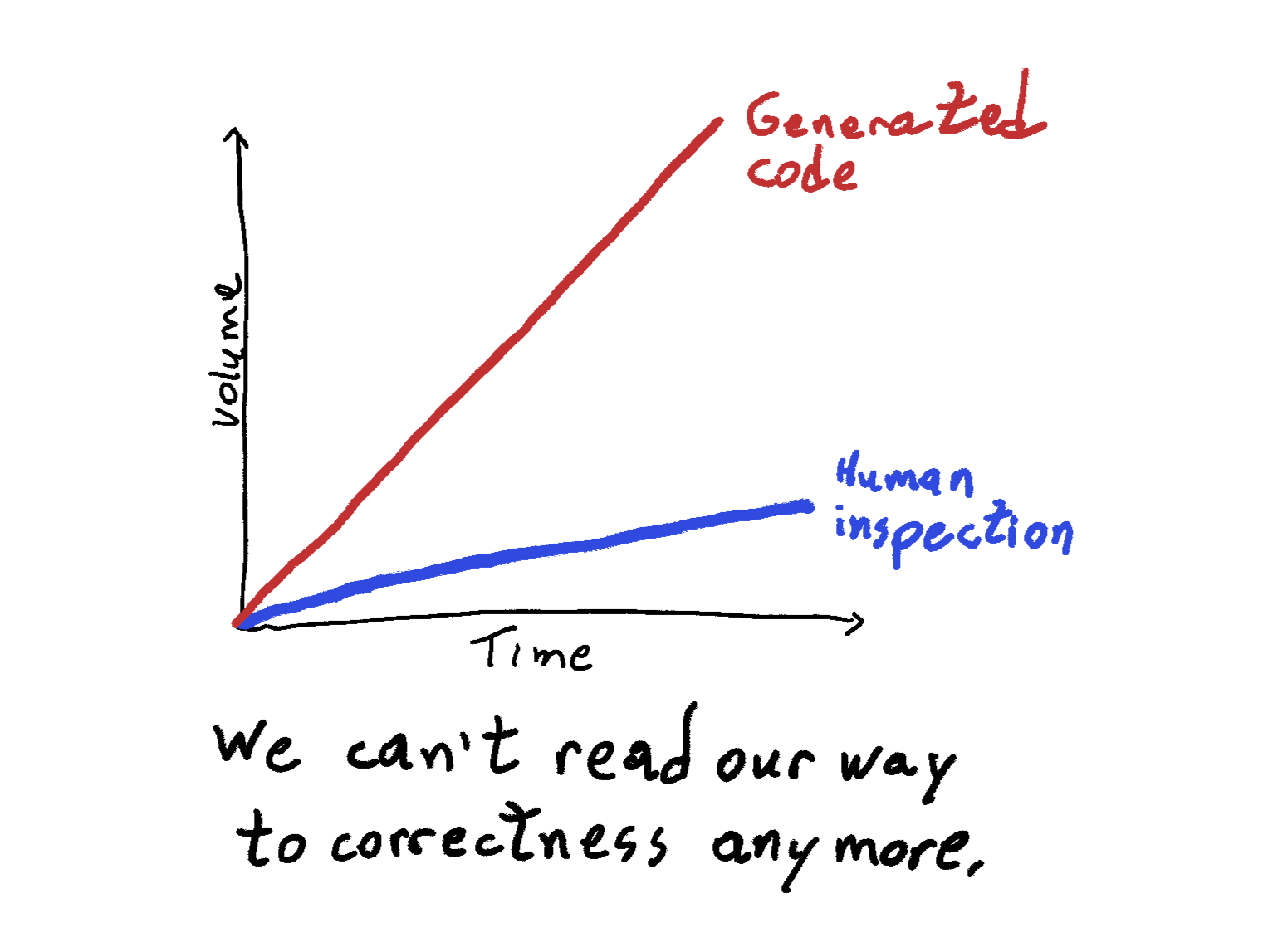
The belief that if the code is read, the system is understood has always been fragile. Modern systems contain hundreds of thousands or millions of lines of code. No engineer truly understands them by reading every implementation detail.
Code inspection mostly worked because code was historically expensive to produce. Implementations appeared slowly enough that humans could keep up.
That economic reality has changed.
LLMs can generate implementations quickly and at scale. Entire features, integrations, and refactors can appear faster than humans can realistically review them line by line. The traditional control mechanism of software engineering, careful inspection of the implementation, stops scaling.
This shift is already visible in what many are calling specification-oriented development. Instead of writing every implementation detail by hand, engineers increasingly focus on describing behavior, constraints, and architectural boundaries, allowing implementations to be generated from those specifications. ThoughtWorks formalized it well.
This article is not about introducing that paradigm. That is already happening. The more interesting question is what follows.
Nor does this mean human judgment becomes unnecessary. The real question is where that judgment should be applied.
Human judgment moves upstream
For years, software engineering relied on a simple mechanism for applying judgment: read the implementation together.
When that mechanism stops scaling, human judgment does not disappear. It moves earlier and higher in the stack.
We got used to asking whether functions were implemented correctly. Those were never the most important questions.
The real questions are about whether the system being built makes sense at all.

What problem is being solved? What assumptions does the design rely on? What constraints shape the space of acceptable solutions? What behavior should the system demonstrate under realistic conditions?
Strong engineering organizations have long recognized this. Design and architecture reviews exist to evaluate the structure of a system before implementation begins.
The reason is simple. Most severe engineering mistakes are not coding mistakes. They are architectural mistakes.
Teams rarely fail because someone wrote an incorrect loop. They fail because the system was structured in a way that made certain failures inevitable.
Generative code makes this shift unavoidable. Spending most of our collective judgment inspecting code becomes a poor allocation of attention. The real leverage comes from shaping the specification, the architecture, and the constraints that define what the system can and cannot do.
This is often where the shift is misunderstood: many observers conclude that AI-assisted coding is useful for prototyping but not for building serious systems. What has changed is not the standard for good engineering, but who can now produce working code.
Implementation used to be a meaningful barrier to entry. Today it is not. When people without system design training develop software, the results reflect that lack of training. That does not reveal a limitation of the tools. It exposes where the real difficulty has always been: deciding what should be built, how it should be structured, and what constraints should govern its behavior.
Seen this way, this shift is less exotic than it first appears. Other disciplines have long relied on specifications and behavioral validation rather than inspecting artifacts directly.
Engineering already works this way in other domains
This shift may feel unusual in traditional software development. But many engineering disciplines have been working this way for years.
When artifacts become too complex to inspect directly, engineers stop trying to understand them line by line. Instead, they rely on specifications, generation processes, and behavioral validation.
Machine learning engineers rarely inspect the internal structure of trained models. They define datasets, training procedures, and evaluation metrics, then evaluate the model based on how it behaves over validation data.
Compilers generate enormous volumes of machine instructions from relatively small programs. Engineers do not read the generated assembly to confirm correctness. They trust the language specification and validate behavior through the compilation pipeline.
Database systems generate execution plans that few developers analyze deeply. What matters is that queries return correct results with acceptable performance.
Across these domains, the artifact itself is not the primary object of scrutiny. Confidence comes from specifications and observable behavior.
Software development is now entering a similar phase.
Architecture defines what the system cannot do
Engineers often describe architecture as the structure of a system. In practice, its real power lies somewhere else: architecture determines what the system cannot do.
Good architecture defines the constraints within which implementations must operate. Services cannot access arbitrary databases. Certain operations must flow through specific interfaces. Critical data paths are isolated behind carefully designed APIs.

This becomes even more important when code is generated by systems trained on the statistical average of existing software. LLMs behave much like competent junior engineers. They can produce locally reasonable solutions, but they tend to replicate common programming patterns, including many common mistakes.
Left unconstrained, generated implementations will often drift toward those average patterns. Architectural decisions counteract that tendency by shaping the space of acceptable solutions before any code is written.
Architectural constraints shape the solution space in which generated implementations can exist. They do not guarantee perfection, but they prevent many of the most frequent failure modes.
Systems of evidence
If code is no longer the primary object of inspection, correctness must be established elsewhere.
Some of those signals we have already discussed. Clear specifications and architectural constraints define what the system is supposed to do and, just as importantly, what it is not allowed to do. They shape the space in which implementations can exist.
Other signals are already familiar to most engineering teams. Automated tests and invariant checks encode expectations about behavior and allow systems to demonstrate that they satisfy those expectations repeatedly. Observability plays a similar role in production. Mature organizations instrument their systems so that behavior can be tracked through metrics, logs, and traces, allowing engineers to detect when reality diverges from the intended design.

But another source of evidence that historically underperformed is system-level validation environments.
The idea was always sound. Observing a system under realistic conditions before production should provide strong signals about its behavior. The problem was rarely conceptual. It was economic.
Building faithful system-level validation environments was expensive. Populating them with realistic data was difficult. Infrastructure often drifted away from production in subtle ways. As a result, many teams relied more on reading code and unit tests than on observing systems in realistic conditions.
That constraint is now weakening.
Generative capabilities make it dramatically easier to provision infrastructure, synthesize data, and recreate environments that resemble production systems. As these production-like environments become cheaper and more faithful, it becomes possible to validate behavior directly rather than reason about it indirectly through the implementation.
Instead of asking whether the code looks correct, engineers can increasingly ask whether the system behaves correctly when exercised with realistic data and traffic patterns.
Death to code review. Long live code review.
Nothing in this shift means code reviews were a bad idea. The intuition behind them was always sound: multiple perspectives surface problems that individuals miss.
What changes is not the value of review, but the dynamics of the code production chain. Humans became the bottleneck mostly because we had no alternative. Code appeared slowly enough that reading it together was the most practical way to apply collective judgment.
That historical limitation is now fading as code generation accelerates and automated tooling can perform much of the inspection work.
Agentic reviewers can analyze implementations far more aggressively than we can. They do not get tired, they do not skim, and they do not hesitate to explore a change from multiple angles.
A reviewing agent can patch the code locally, generate additional tests, execute them, and probe edge cases the original author never considered. It can search documentation and external sources while reviewing the change, compare patterns across the repository, and inspect interactions that would be tedious for a human reviewer to reconstruct manually.
Things become even more interesting when different models review each other. Different models tend to care about different things. In practice, they sometimes disagree in amusingly polite ways in pull request comments. One model worries about performance implications, another pushes on edge cases, and Gemini, in my experience, behaves like a particularly enthusiastic DRY enforcer.
Paradoxically, stepping out of the way of implementation review may actually improve quality. Machines can inspect code more exhaustively than we ever could, while humans concentrate on the decisions that shape the system itself.
Containment instead of inspection
At this point, an obvious objection appears: if generated code is pushed without careful inspection, the consequences could be severe. Data leaks, outages, corrupted systems, or failures that threaten the business.
This concern is legitimate.
But manual inspection was never a robust safety mechanism. Human reviewers routinely miss subtle issues in complex systems, not only related to safety but also to functional correctness and other non‑functional properties.
Mature engineering organizations solved this problem in a different way: not by perfect inspection, but by designing systems that contain failure.
Architectural boundaries prevent services from accessing sensitive data arbitrarily. Deployment systems gradually expose changes through feature flags and canary releases. Monitoring systems detect unexpected behavior quickly. Automated rollback mechanisms limit the blast radius of failures.
These mechanisms do not try to guarantee that mistakes never happen. They assume mistakes will happen and ensure that their impact remains limited.
The goal is not to eliminate mistakes entirely. That has never been realistic.
The goal is to design systems that prevent mistakes from easily escalating into systemic failures or severe consequences.
When implementations become cheap
The deeper shift behind all these changes is economic.
When implementation is expensive, engineering effort concentrates on writing and reviewing code. When implementation becomes cheap, the scarce resource becomes clarity: clarity about the problem, the architecture, and the system's expected behavior.
This reveals something that was always true but easier to ignore. Reading the code was never a robust way to establish correctness. It was simply the most practical one when code appeared slowly enough for humans to inspect it.
As implementations become abundant, that limitation becomes visible.

Confidence has to come from somewhere else. Clear specifications. Architectural constraints. Tests. Staging environments. Observability. Production feedback. Not from how convincing the implementation looks, but from how the system behaves.
Implementation still matters, but it is no longer the primary object of attention.
Machines writing code is not the real disruption. The disruption is realizing that reading the code was never how we truly knew whether a system worked.